Lieber Charles, nachdem neue KI-Werkzeuge zur Generierung von Content zur Verfügung stehen, werden sie auch eingesetzt. Sie können die Menschen produktiver machen und die kreative Arbeit auf eine neue Stufe heben. Allerdings muss man den Umgang mit den neuen Werkzeugen erst erlernen. Neue Suchmaschinen werden möglich, die mit natürlich formulierter Sprache kommunizieren können, ganz neu ist Perplexity.
Es kann aber auch viel Unsinn erschaffen werden, und die neuen Möglichkeiten werden sicher auch zur Erzeugung von destruktiven Inhalten genutzt: Fake News und Propaganda kann man damit in einem ganz anderen Ausmaß erzeugen lassen. Die Modelle zur Erzeugung von Texten können dabei schlüssige Argumente für eine Sache liefern, aber auch genausogut den entgegengesetzten Standpunkt einnehmen. Es drängt sich die Frage auf, ob es einen Weg gibt, herauszufinden, ob der Text von einem Menschen oder einem Computerprogramm stammt.
Auf den ersten Blick wirken die Texte sehr natürlich und als Lesende können wir uns hier nicht sicher sein. Der Turing-Test lässt grüßen (vgl. „Unterwegs im Cyber-Camper“ S. 424). Aber könnte denn ein Computerprogramm herausfinden, ob der Text generiert wurde oder nicht?
Tatsächlich gibt es seit kurzer Zeit Programme, die das offensichtlich können, beispielsweise das frei zugängliche, nicht kommerzielle Tool GPT-2 Output Detector Demo. Ein Princeton-Student hat über Weihnachten eine Webseite aufgesetzt, die es nicht-Fachleuten erlaubt, Texte über ein Eingabefeld abzuschicken: GPTZero.
Das Programm entscheidet dann, ob der Text vom Menschen stammt oder nicht. Die Nachfrage ist riesig, und so ist die Webseite meistens überlastet. Nun frage ich mich, lieber Charles, wie sicher diese Einschätzung ist. Zum Ergebnis wird eine Wahrscheinlichkeit angegeben, wie plausibel diese ist (Likelihood).
Das ist schon mal sehr interessant, und das Programm kann also nicht mit absoluter Sicherheit eine Einschätzung geben. Es funktioniert auch offensichtlich besser, je länger der Text ist. Klar, je mehr Daten, desto mehr verräterische Muster sind eventuell vorhanden.
Aber nichts würde einen Menschen daran hindern, auch einen Text zu erzeugen, der ähnliche Muster wie generierte Texte aufweist. So könnte es zu fatalen Fehleinschätzungen kommen, beispielsweise, wenn eine akademische Arbeit (oder Teile davon) fälschlicherweise als automatisch generiert eingeschätzt wird. Überhaupt muss man sich der Frage stellen, ob das nicht legitim ist und ob man sich bei trivialen Textpassagen nicht einfach dieses neuen Werkzeuges bedienen kann.
Aber welche unsichtbaren Merkmale sind nun im generierten Text vorhanden, die Menschen offensichtlich nicht erkennen können und wie kann man diese finden? Ein Problem ist, dass man den Quellcode und damit die Funktionsweise von GPT-3, dem Algorithmus von OpenAI, bisher nicht einsehen kann. Aber die Vorgänger-Version, GPT-2, ist Open Source, also für alle Programmierer frei zugänglich. So basiert GPTZero und andere ähnliche Programme auf dieser Software. Aber anscheinend kann man damit genauso gut Texte, die von GPT-3 (wie von ChatGPT) erzeugt wurden, erkennen.
Lieber Charles, das wichtigste Merkmal, nach dem der Entlarvungs-Algorithmus sucht, ist die Perplexität, also „Verblüffung“. Das bedeutet, wenn ein neuer Satz vom Computer auch so ähnlich entworfen worden wäre, tendiert er zu der Einschätzung, dass er automatisch generiert wurde. Wenn hingegen ein Satz kommt, der den Test-Algorithmus perplex macht, ist er eher vom Menschen erzeugt. Ist das nicht verblüffend, lieber Charles?
Warum der Algorithmus von einem Satz verblüfft ist, kann man dabei nicht genau sagen, da der Algorithmus eine Black Box ist, wie alle neuronalen Netze, die hier ebenfalls die Grundlage sind. Lieber Charles, ich habe selbst ein Programm geschrieben, das die Perplexität ermitteln kann, ähnlich GPTZero. Hier siehst Du zwei Diagramme, die mein Programm erzeugt hat und die zeigen, wie hoch die Perplexität für die einzelnen Sätze ist.
Ich habe zum Test zwei Texte verwendet, einen selbst geschriebenen und einen von ChatGPT generierten (ähnlich der Geschichte aus dem vorherigen Blog). Beide Texte sind exakt gleich lang. Hier die Diagramme:
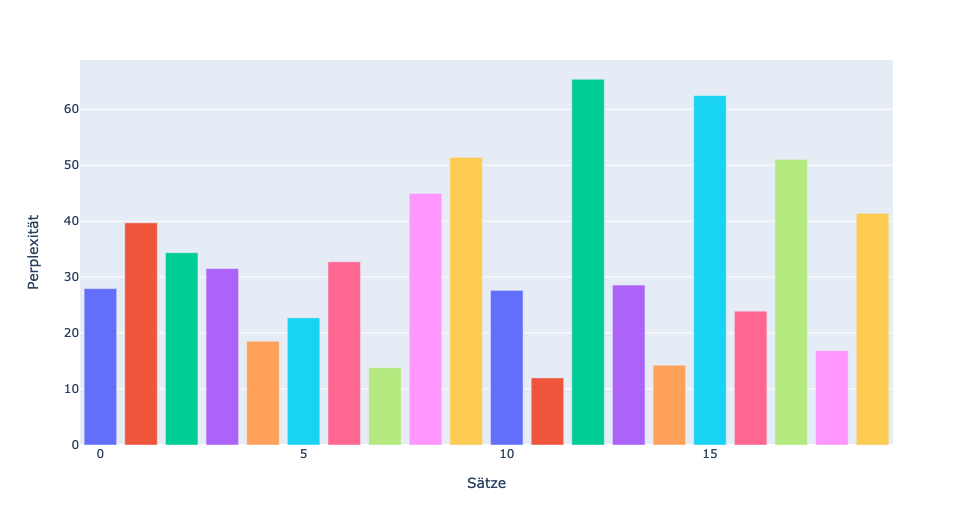
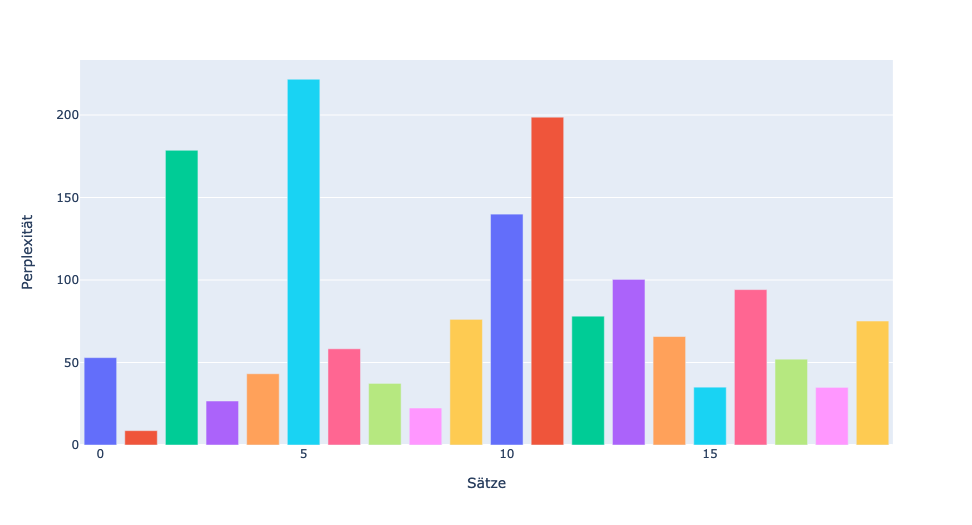
Man kann gut erkennen, dass die durchschnittliche Perplexität bei dem selbst geschriebenen Text viel höher ist, nämlich 80. Beim Text con ChatGPT ist sie nur 33. Somit scheint es möglich zu sein, herauszubekommen, ob ein Text computergeneriert ist oder nicht. Ich bin gespannt, ob das so bleibt oder ob zukünftige Sprachmodelle nicht noch besser werden, im Punkt Perplexität, und uns noch mehr verblüffen.